
If you’ve been following, you may have noticed that though I defined three basic parameters, S, E, and D, I only used two of them. If it wasn’t clear before, I’ll explain the details of these three parameters:






These terms can be broken down further:
alias:
The identifier is any uniquely hashable identifier.
The quantum is any SI unit that can be used to describe a quantity of r.
The dependencies are an n-ary set of identifiers describing the composition of r.
The properties are an n-ary set of relationships to physical forces or other resources.
The coefficients 


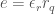

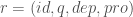
As I noted previously, P is the parity value for a given resource, defined like so:
And represented by the shorthand 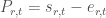
I will define another term, the fulfillment, to represent the parity between supply and demand:
Finally, there is a relationship called the mismatch, which describes the difference between parity and fulfillment.
M can also be expressed as a percentage of demand; in this case I use the Japanese hiragana み (mi), which unfortunately does not parse with the LaTeX packages used by WordPress. It is defined as:
み




Possible reasons for a negative mismatch between exploitation and demand:
- Spatial problems: The product or service is desired but inaccessible to certain users.
- Exploitative lag: The demand has grown since the last production run, and exploitation is simply behind. Unlike in a capitalist economy, this is only considered problematic for resources whose priority is negative.
- Demand exceeds supply: This is the most problematic reason. In this case, production should be slowed or stopped entirely and relevant users alerted that an alternative resource should be found as soon as possible.
Possible reasons for a positive mismatch between exploitation and demand:
- Spatial fragmentation: Spatial reasons prevent a more minimal configuration from working.
- Store and wait: Demand is diminishing but the resource has not been deallocated yet.
- Shortage prevention: The resource is being strategically overproduced or overexploited in order to prevent possible shortages.
Possible reasons for a positive or negative mismatch:
- Automated processes: Production or exploitation was at least partially automated and the output estimate was inaccurate.
- Inaccurate sampling: Demand estimation is subject to statistical biases.
These two should always be considered when using those data. It’s important to continually re-check all three basic parameters in order to ensure the economic system does not exhibit chaotic behavior. It would probably be advisable to use a 95% confidence interval in practice.
This brings up the question of how are each of these measured?
Supply:
- Survey: For natural resources, such as metal ore, stone, wood, a survey must be done. This already happens today, but except when they are carried out by government agencies such as the USGS, the data is often kept private or paywalled.
- Inventory count: For products, an inventory will be created at the time of production and periodically re-checked.
Exploitation:
- Inventory count: For natural resources, an inventory process similar to the one described above may be used.
- Usage statistics: For products, data on their actual usage can be collected using the products themselves or specialized instruments.
- Supply diffing: For consumable products, a negative change in supply can be considered exploitation.
Demand:
- Polling: Sample statistics may be used to get a general overview of demand. This would be the primary method for detecting mismatch.
- Preordering: Allow users to preorder a product that has not yet been released. This is good for new products and high-volume production runs.
- Analogous data: New products are usually similar to existing ones, and the demand for an analogous product may be used as a basis for estimating new demand.
Again, notice that no specific technology is required for any of the concepts described so far. Computers make these calculations far easier, but for a small enough community, it would not necessarily be a requirement. Natural economics is primarily a social and methodological change, not a technical one. However, in acknowledgment of the power of computing, there is a lot of room to expand to more complex configurations (e.g. dependencies and properties are not necessary but are infinitely scalable). That aspect of its design will require people other than me working on it, of course.
A more formal treatment of much of the information above can be found on my original blog: Post 1 Post 2
