
As I’ve covered before, a computational economy uses preemption and priority levels for its allocation schemes. Priority levels are used to determine, when demand exceeds constraints, which demands to fulfill and which to ignore. Previously I mentioned that these would be set arbitrarily at the start until a more rigorous definition is created. Well, I have now created a rough definition, though it will require quite a bit of effort on the survey and data mining side to get it working properly.
I think it will be easier if I show the formula and explain the terms in order. If you don’t recall, I had intended for this to fit within a range of about 120 discrete levels. However, two of the terms here are definitely not integers. I will undoubtedly have to weight some of them or just replace exact values with categories. and the resulting value will simply be rounded down and truncated above 100 (remember, the range is [rt,iso,-19,…,0,…,100] with the leftmost (lowest, after rt and iso) value being the highest priority.
![PRIO = -k\left [t_{aff,0}(\tilde{a})+t_{aff,1}(\tilde{ECO})-\hat{ARA}+|Dep_{in}|-|Dep_{out}|\right ]](https://s0.wp.com/latex.php?latex=PRIO+%3D+-k%5Cleft+%5Bt_%7Baff%2C0%7D%28%5Ctilde%7Ba%7D%29%2Bt_%7Baff%2C1%7D%28%5Ctilde%7BECO%7D%29-%5Chat%7BARA%7D%2B%7CDep_%7Bin%7D%7C-%7CDep_%7Bout%7D%7C%5Cright+%5D&bg=ffffff&fg=444444&s=0&c=20201002)




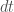



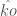

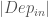

Clearly more work needs to be done, as I’m not even fully certain if I’ve covered everything that should be covered, or if the one term can be dropped. Like, I just realized I should include the time to failure and perhaps the maintenance cost of the product. Other parts of NE will likely be implemented long before there is data comprehensive enough to use this kind of formula, so heuristics will do well enough to start.
The basic idea I’m trying to capture is that tools of creativity, things that have a positive effect on others or the ecosystem, and efficiently-made products should be prioritized above destructive, detrimental, and wasteful products. Guitars over guns, gasifiers over coal furnaces, flowers over tobacco. This is not to say we can’t have the latter in each case at all, but it would be better if we instead had the former, and if it comes down to one or the other, we should certainly choose the healthier alternative.
An aside:
One thing I’ve learned in writing this entry is that though I am trying my best to keep this scientific, there is quite a lot of room for improvement. What ended up here differed significantly from my original notes, as I thought critically about the math here. However, it is important to note that I actually am critical of everything I’ve done, which is why I still feel I am being scientific, and why there is a bit of inconsistency over time.
Though this work (as in all of NE) was originally sparked by The Venus Project and The Zeitgeist Movement, I have grown to feel increasingly uncomfortable being associated with them, as I continually see a lack of self-criticism and quite a bit of groupthink among their members. One of the reasons I avoid explicitly mentioning any group associations here is the ingroup/outgroup biases that any readers would have given that knowledge.
I’d also like to mention that my friend Pieter de Beer, who curates the pages on VIAAC theory, has decided to move back to Durban and attempt to implement, test, and publish research on our ideas. I am very excited about this, as I’m sure he is, and it’s got me wondering what I can do once I graduate. Interestingly, I found out that we independently had the idea of starting with community kitchens, though the reasoning that went in and the idea that resulted differed slightly.
